Data-efficient PBR learning
High-quality relightable avatars are learned from fewer than 100 real 3D scans with a Blender-augmented synthetic data pipeline.
ECCV 2026
MARCUS-Avatar turns a single portrait into a relightable 3D avatar with render-ready geometry and physically meaningful intrinsic materials.



High-quality relightable avatars are learned from fewer than 100 real 3D scans with a Blender-augmented synthetic data pipeline.
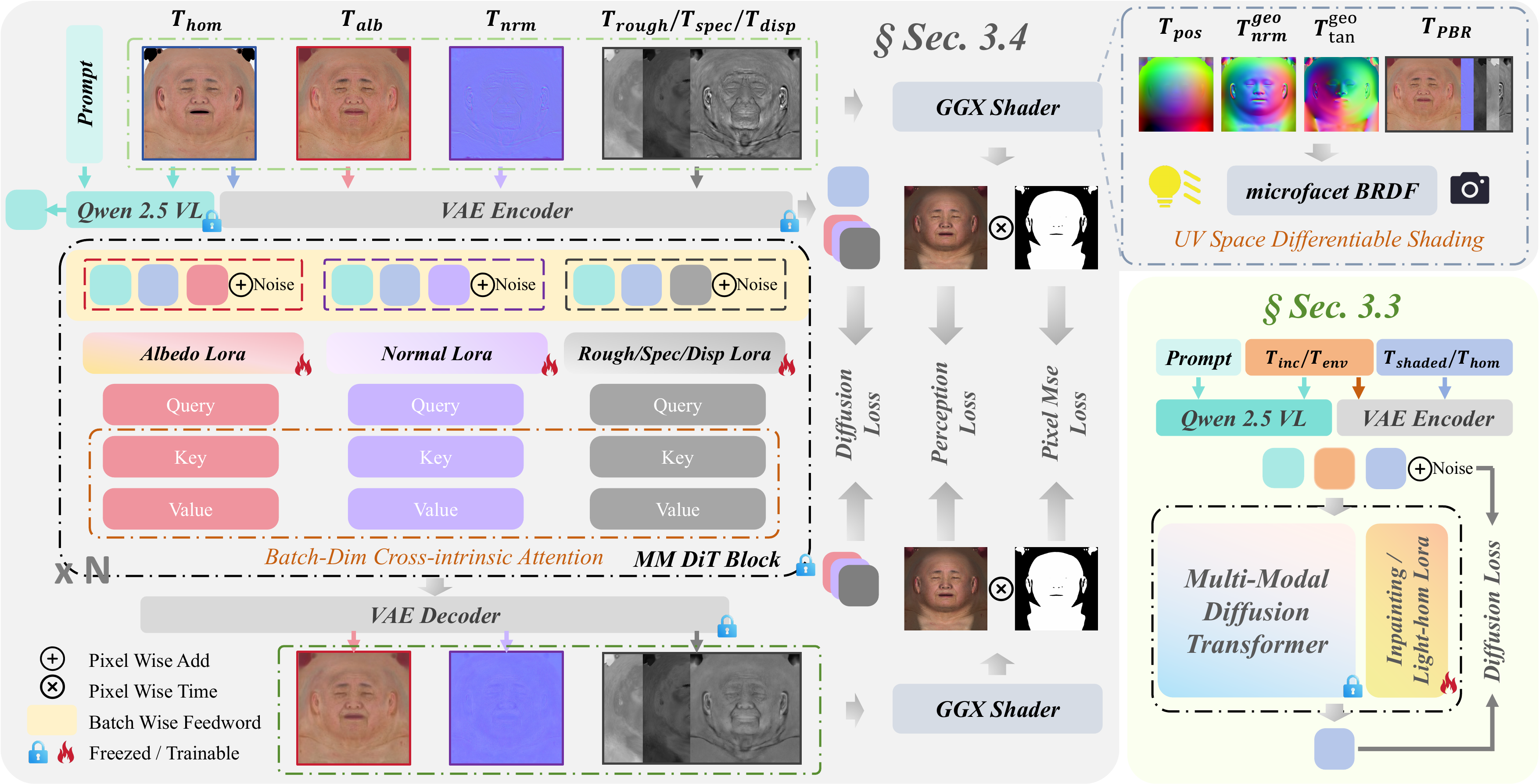
A unified diffusion backbone uses task-specific LoRA adapters for UV texture inpainting, delighting, and intrinsic PBR material estimation.
Cross-Intrinsic Attention and UV-space differentiable shading align albedo, normals, roughness, specular, and displacement into coherent 4K assets.
Overview
The teaser summarizes the full output space: aligned input, recovered geometry, intrinsic material maps, and relit renderings from a single in-the-wild image.
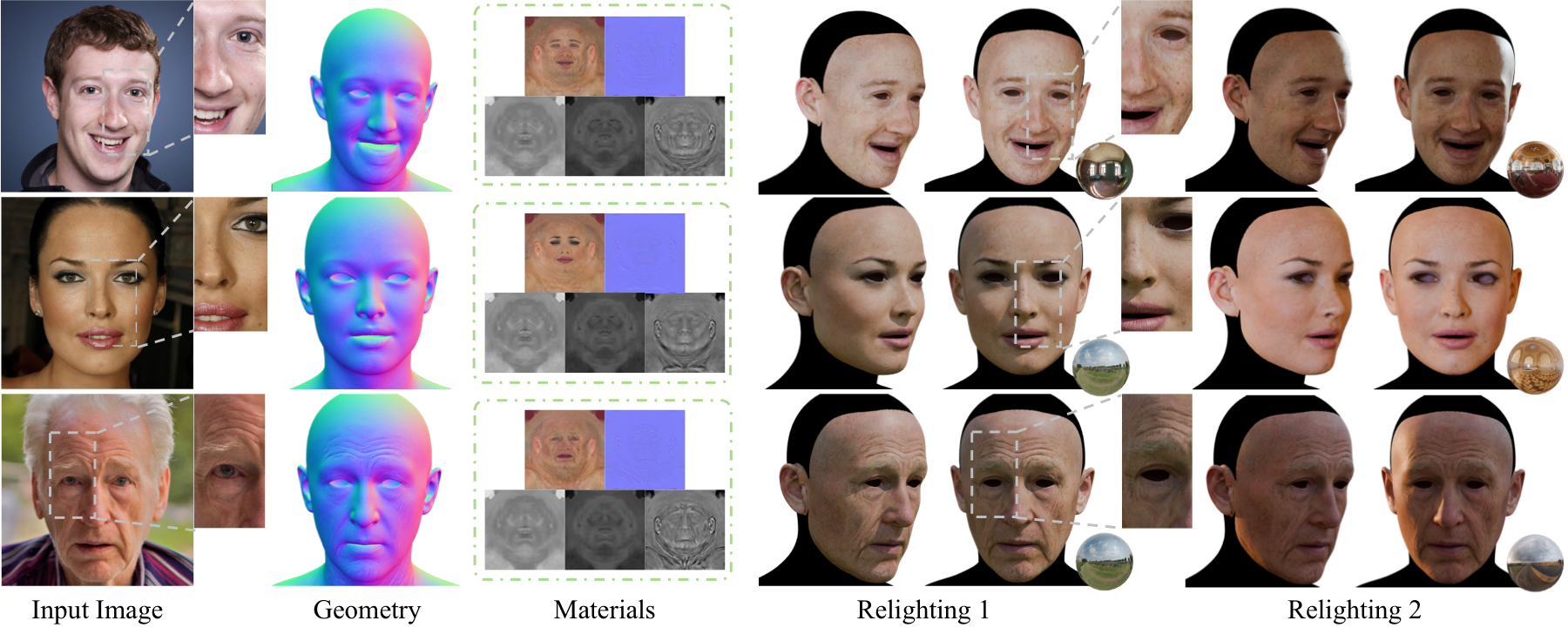
Generated 3D Assets
Browse converted GLB outputs reconstructed from single portraits. The full material view shows the relightable avatar appearance, while the gray geometry view reveals fine facial structure.
3D viewer or model failed to load. Please check WebGL support and GLB access.

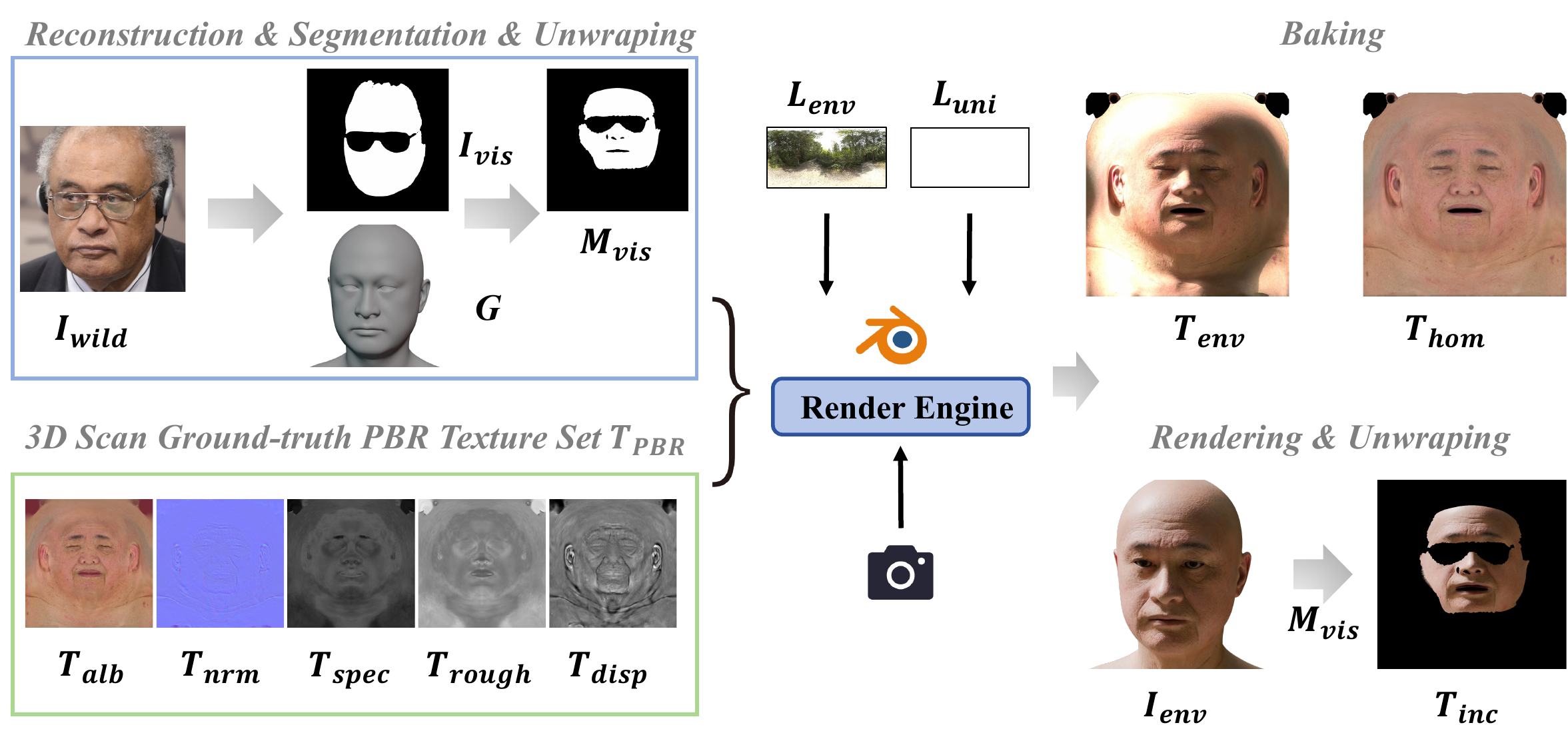
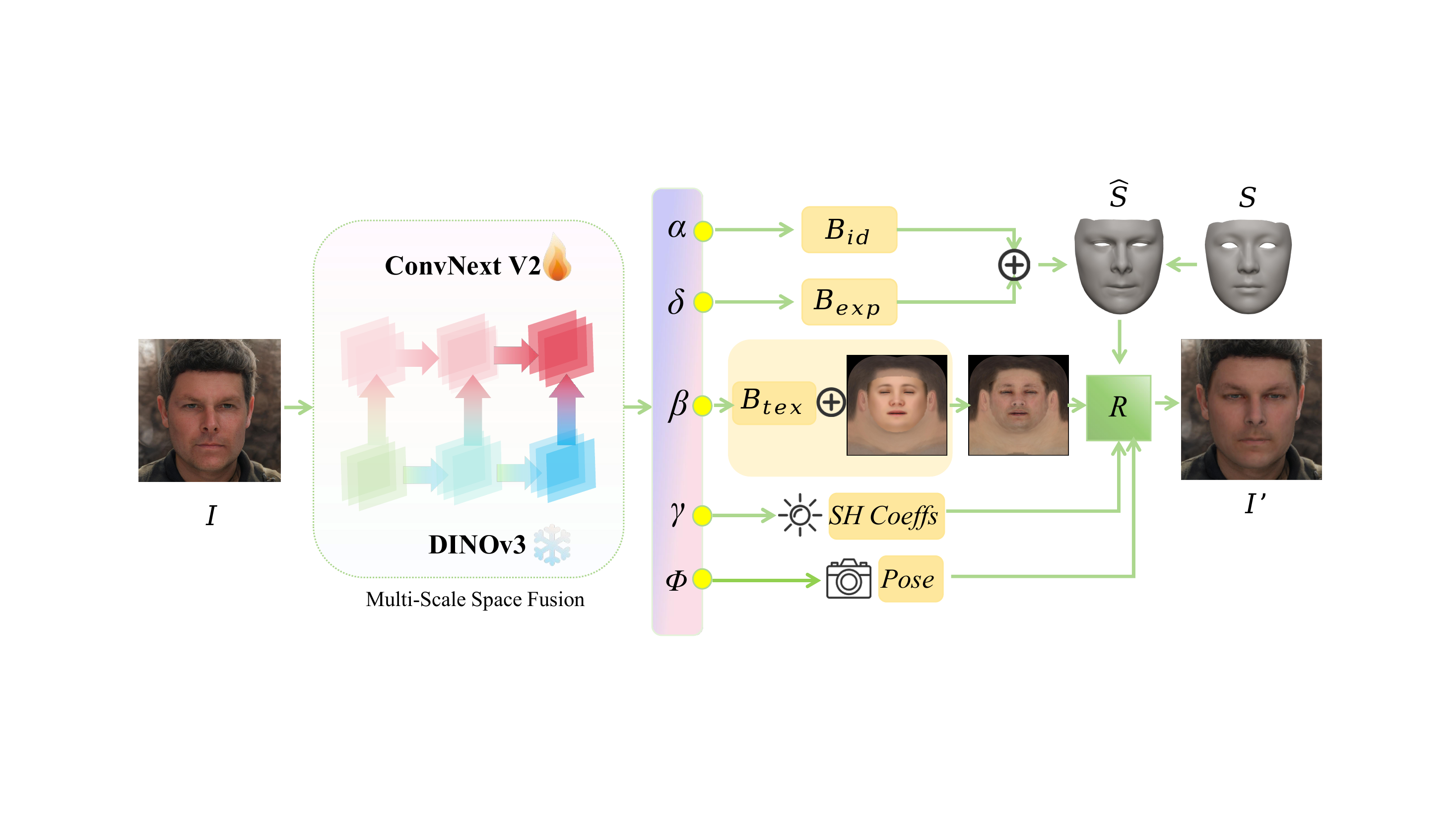
Pipeline
The paper pipeline combines geometry alignment, UV-space texture completion, light homogenization, intrinsic material generation, and UV-space differentiable shading.

Evidence
Complete material estimation enriches geometry through normal and displacement maps. UV diffusion completes occluded textures and removes baked-in illumination while preserving high-frequency identity cues.


Citation
@inproceedings{marcusavatar2026,
title = {Monocular Avatar Reconstruction via Cascaded Diffusion Priors and UV-Space Differentiable Shading},
author = {Anonymous Authors},
booktitle = {European Conference on Computer Vision},
year = {2026}
}